記事の詳細
Adobe Acrobat Document Cloudの自動OCR機能を使って画像になっているテキストを抽出する方法

Acrobat DCは、世界で最初に開発されたデジタルドキュメントフォーマット「PDF」を直接編集したり、チーム内でドキュメントをレビューしたりすることが出来るPDFソリューションです。
今回のブログの見出しはコチラです!
PDFとAdobe Acrobat DCは?
MicrosoftOfficeやAdobe製品を利用してドキュメントを作成して、誰かに送付等するとき、必ず拡張子「pdf」のファイルが利用されます。PDFは「Portable Document Format」の略で、Office製品などのソフトウェア、ハードウェア、OS問わず、文書を確実に表示、交換するためのファイル形式です。
今では大概のソフトウェアにこの保存形式がデフォルトで搭載されています。見積書や納品書などをデータで送る際もよく利用されます。
もちろん、パソコンで作ったものだけでなく、手描きしたイラストをスキャナーなどで読みこみ、保存形式をPDFに変換して保存すると、これらもきちんとPDFファイルとなります。
パスワードで保護したり、長期の保存が可能だったり、何かと便利なPDFです。Acrobat DCは、このPDFに対して様々なアクションができるアプリケーションなんですね。
Adobe Acrobat DCのOCR(Optical Character Recognition/Reader)、光学文字認識
Adobe Acrobat DCは、自動的にOCRをバックグラウンドで認識して、ドキュメント内にあるフォントを認識し、文書を編集可能な画像とテキストに変換してくれます。多少ラグはありますが、表示中のページを一つずつ処理してくれます。
Photoshopで作成し、PDF保存するときに「Photoshopの編集機能」をオフした画像もご覧の通り。
before

after

ただし、ここまで複雑な絵だと、編集作業もうまくはいきません。が、もっと単純なチラシだと、うまくいく場合があります。
例えば、FAXで届いたこのチラシ。
before

after

こんなふうに編集することが可能です。
実際に画像を編集したいときの方法
1.編集したいPDFファイルを開きます。
用意したPDFは、Adobe Illustratorで作成し、アウトライン化してIllustratorの編集機能をオフにした状態で保存したPDFファイルです。
矢印部分を押すとメニューが展開します。
2.「PDFを編集」をクリックします。
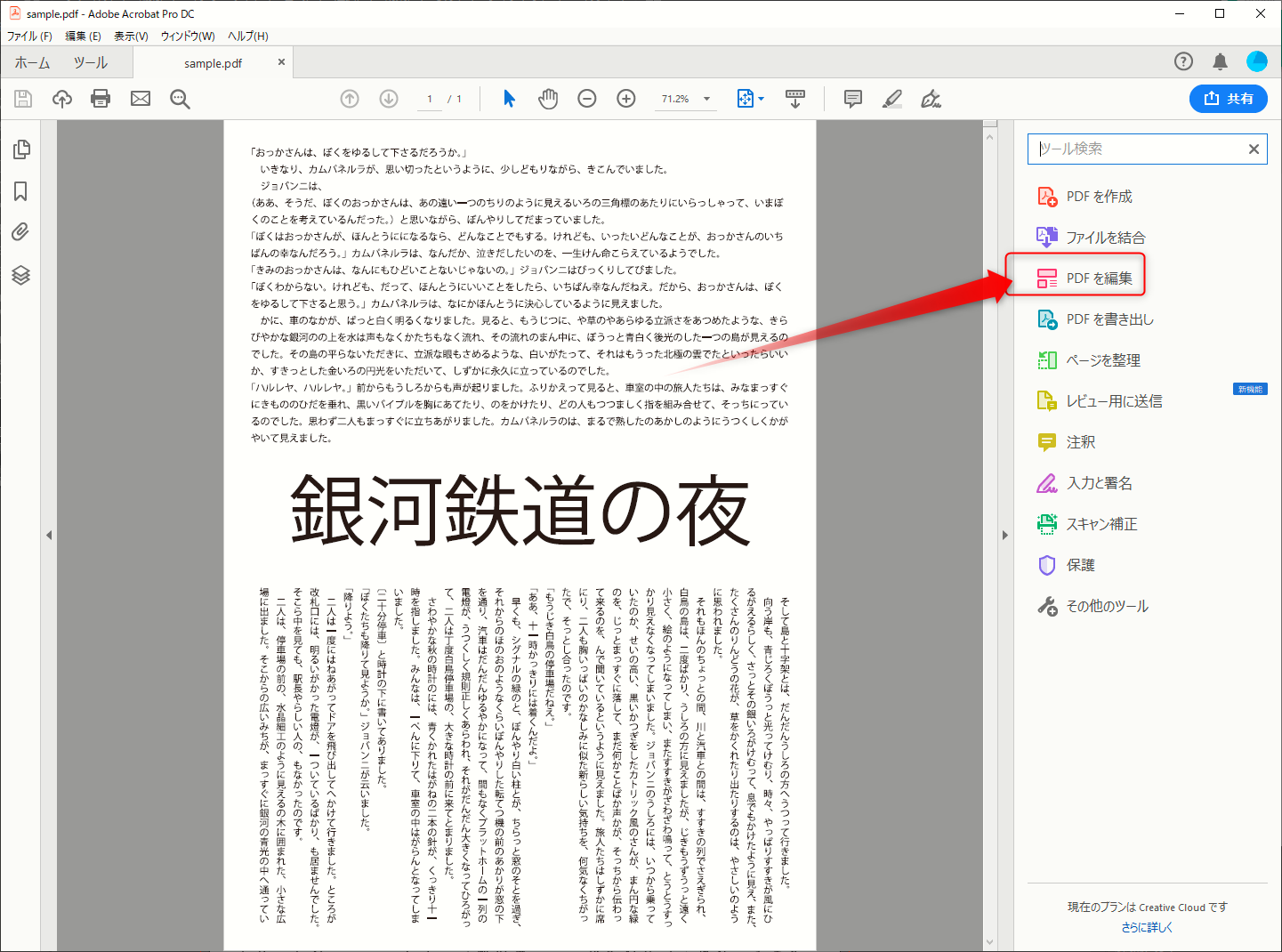
自動的にスキャンしたページを編集可能なテキストと画像に変換してくれます。これには少し時間がかかります。
以下のような注意書きが表れますので、任意で設定します。
設定し忘れた場合は、メニュー右下の「スキャンした画像」の「設定」から同じプロパティを展開することができます。

言語を日本語に設定します。
スキャンが終わった様子がこちら。
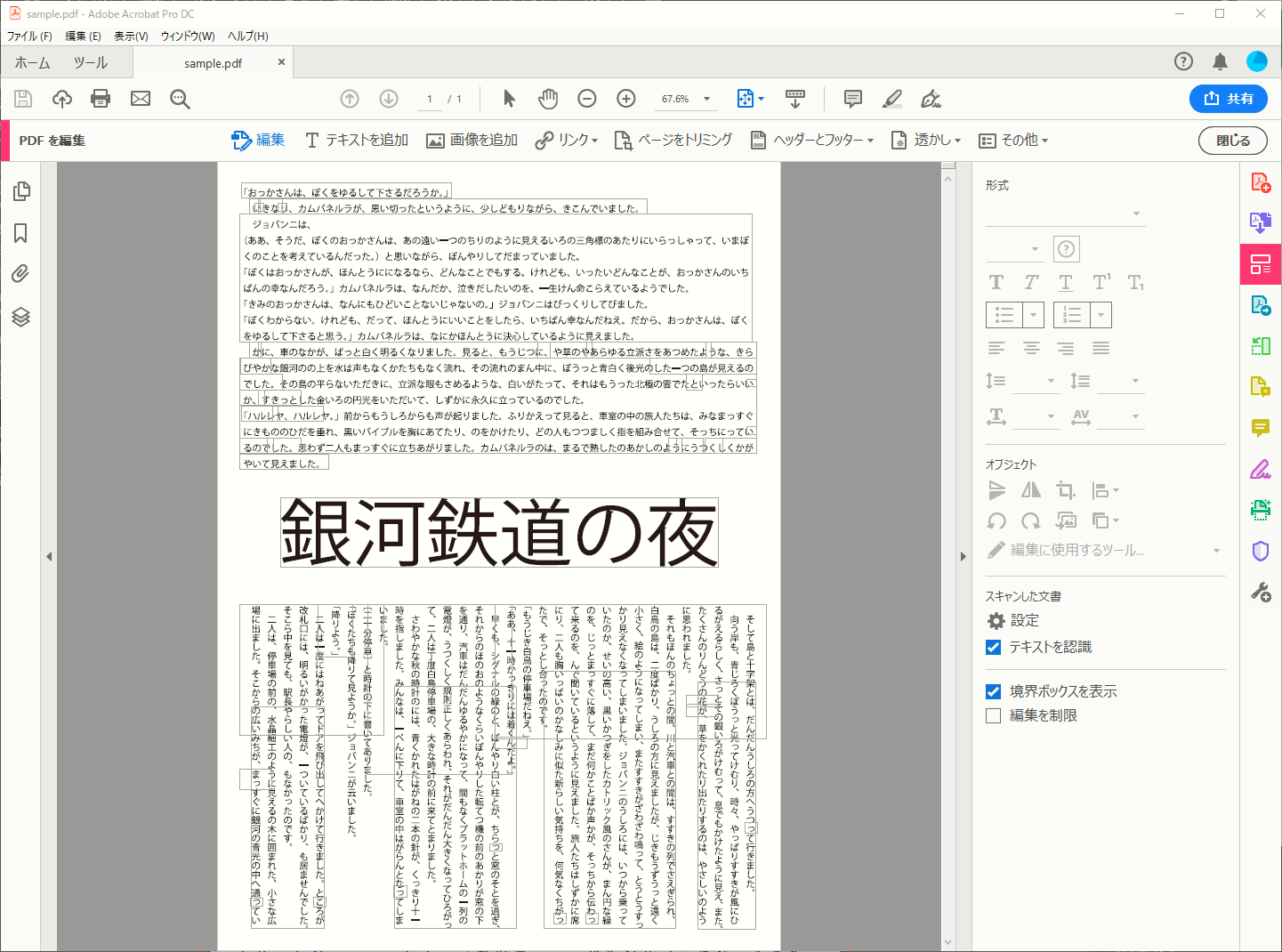
OCRの精度は?
横書きだとほぼ問題ないのですが、縦書きの場合はいくつものバウンティボックスが見えている通り、時々画像になってしまう場合があります。
文字として残っても、以下のようなテキストになってしまうこともしばしば。
【原文】
そして島と十字架とは、だんだんうしろの方へうつって行きました。
向う岸も、青じろくぽうっと光ってけむり、時々、やっぱりすすきが風にひるがえるらしく、さっとその銀いろがけむって、息でもかけたように見え、また、たくさんのりんどうの花が、草をかくれたり出たりするのは、やさしいのように思われました。【スキャン後】
そして島と十字架とは、
向う岸も、青じろくぽうっるがえるらしく、さっ
に思われました。
他の文章で試してみると、「言」だったり、「一」「二」と言った文字は、縦書きだと微妙な部分が多く、一つ一つを見直す必要がありそうです。
横書きのPDFファイルであれば、文字の抽出やテキストデータに直すのはそれほど苦痛ではなくなりそうです。ぜひ試してみてくださいね!
この記事であなたの課題を解決することができましたか?
疑問点があったり、解決できなかったことがありましたら、お気軽にご相談してください。

ほかの投稿も読んでみませんか?








相模原のお店やサービスをどんどん紹介!

飲食店





サービス











